

Posted on Nov 12, 2024 by Rhishikesh Joshi in DataLake | Infrastructure | Azure | AWS | GCP
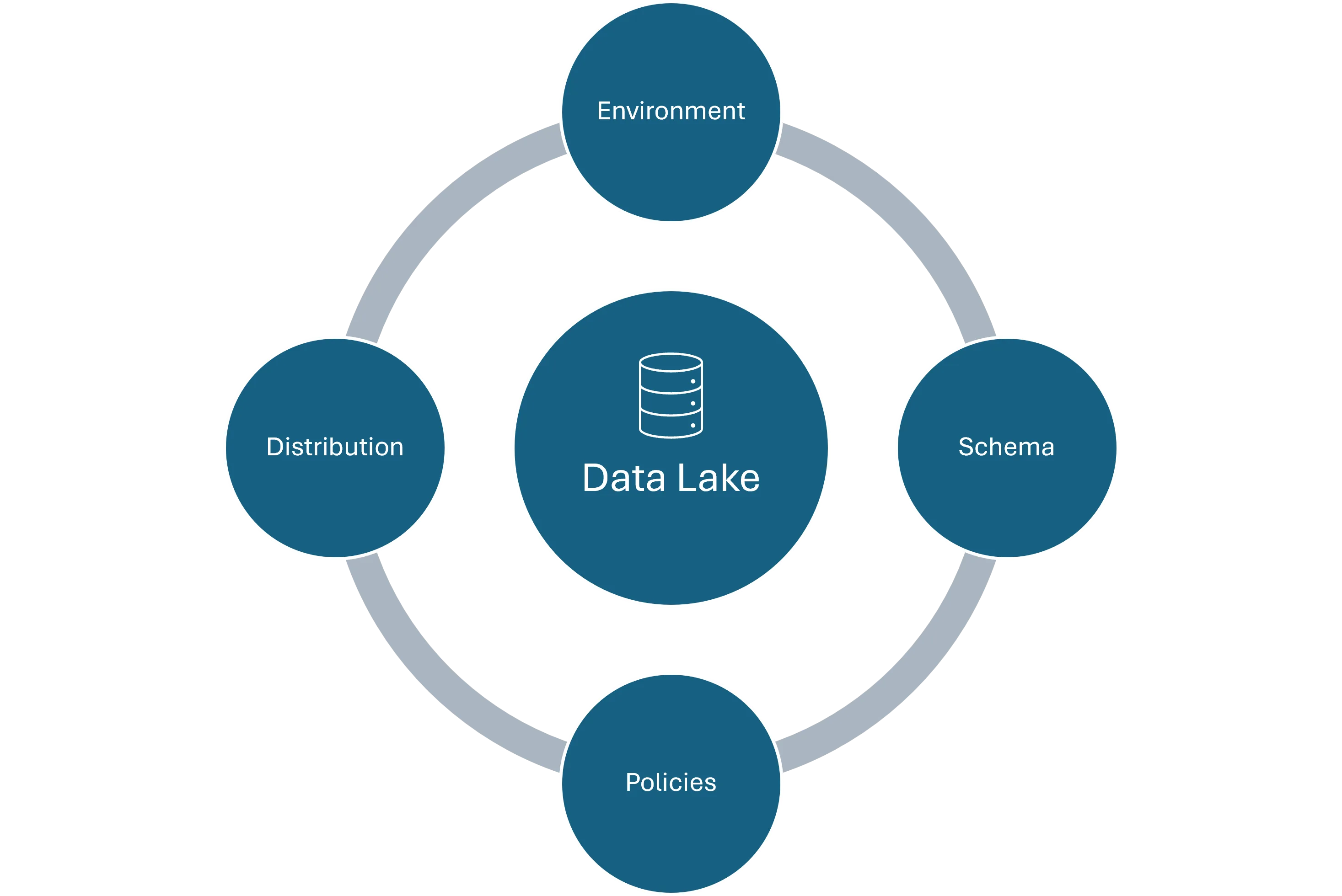
Over the years we have had the opportunity to setup data lakes for our clients. We have worked on key cloud platforms like Azure, AWS and GCP. In this blog I have consolidated my learnings into creating a 4 pronged framework to building a DataLake.
- Environment Considerations
- Schema Design
- Policy Definition
- Data Distribution
Environment Considerations:
When you are in the whiteboard phase of your data lake design, ensure that you have provisioned your infra for development as well as production. A few things that you might want to keep in mind at this stage are:
- Selection of a Cloud Service Provider – Cost, Features and Adaptability concerns – https://venanalytics.io/aws-vs-azure-vs-gcp-perspective-on-features-and-costing/
- Data Sources – What are the types of data source you intend to onboard? Structured/Unstructured/Semi-structured?
- Sizing – What would be the size of your dev and prod environments?
- Costing – How much is data ingress, egress, storage and backup costs? Please note most platforms charge for egress and storage.
- Data Duplication – What percentage of prod data will be held in your dev env?
- Retention Policy – How often do you plan to prune the dev data?
- Data Validation – What qualifies for a quality data? Define quality KPIs
Answering these key questions will direct you in setting up your environments.
Schema Design:
Before designing the actual schema, you need to finalize the type of data model you intend to build that will best solve your business case. There are broadly 3 types of Data Models –
- Dimensional Data Model – Data stored as Facts and Dimension Tables
- 3NF Data Model – Data stored in highly normalized tables
- Data Vault – Data stored in Satellite tables and connected by links
Here’s a video that will help you understand these data models in detail – https://www.youtube.com/watch?v=l5UcUEt1IzM
Once the schema type is finalized, only then start designing each component of the schema. At this point ensure that the right business stakeholders as involved for approvals and suggestions.
Define Data Base Policies:
Database maintenance is as important as the setup itself. The robust policies that we define at the beginning will go a long way in delivering quality data to the right people at the right time and reduce maintenance overheads. A few policies can be:
- Access management policy
- Data purging and backup policy
- Policy pertaining to Database performance.
- Time out policy
- Quality Control
Defining a few SOP’s at the start can also go a long way. For example, if the end user requests to onboard a new data source – Important things to define would be TAT, Owner, Approval Matrix, etc.
Data Distribution:
In order to distribute the right data to the right people for the right duration is imperative. Reporting data can be distributed as data models rather than raw data itself. For example, team members can connect to published Power BI models thus saving hours in data modelling. This also ensures that the data quality is centrally governed and so is access control.
Here’s a pictorial representation of the difference between the old approach (Direct Access to data base) vs access to Power BI Data Model.
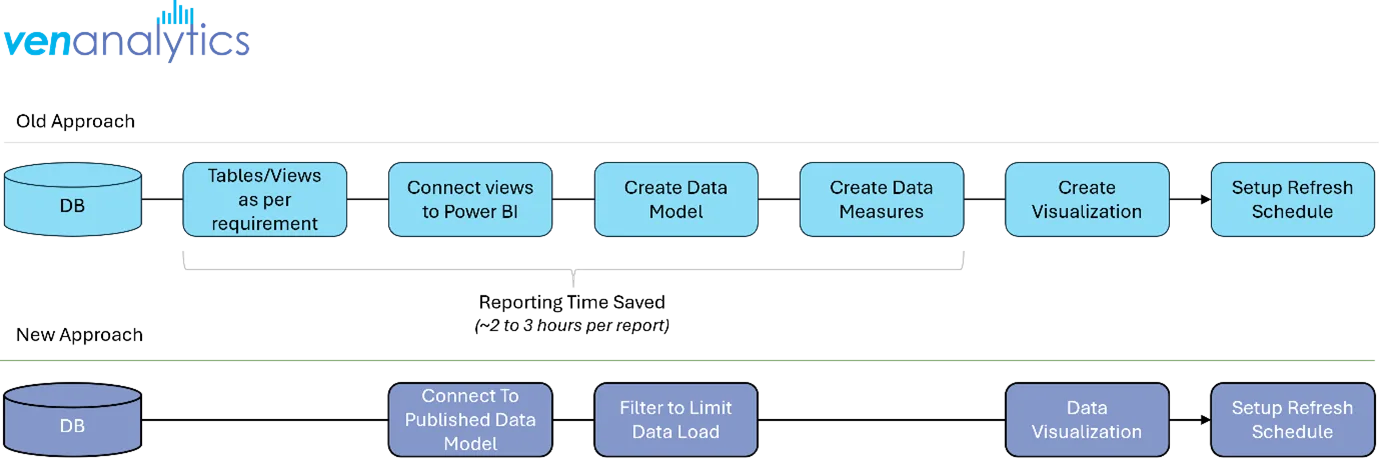
We believe that on an average we save up to 2-3 hours of time per analyst that he would spend in understanding and re-creating the data model.
The 4 key points mentioned above provide you with a basic framework to initiate your DataLake Project. The above framework is ideal for reporting needs of a midsize organization.
Please drop us a mail on hello@venanalytics to get a free consultation for your Data Lake Setup!